Web Crawler spielen in Zeiten immer wichtiger werdenden Contents im Netz eine entscheidende Rolle. Denn nur mit Automation können Suchmaschinen wie Bing, Google und Co. gezielt die für sie relevanten Inhalte aus zahllosen Websites, Unterseiten und Mediendateien herausfiltern. Der Begriff Web Crawler, zu Deutsch „Internet-Krabbler“ ist dabei durchaus wörtlich zu nehmen – warum, erfahrt ihr in diesem Beitrag.
Allgemeines zu Web Crawlern
Gebt ihr bei einer Suchmaschine eurer Wahl eine Anfrage, etwa eine Dienstleistung oder ein Produkt, ein, werden euch die Suchergebnisse in einer bestimmten Reihenfolge angezeigt. Diese ist aber keinesfalls zufällig, sondern basiert in erster Linie auf automatisierten Auswertungen der Inhalte auf den entsprechenden Seiten. Die „Bots“, die für diese Auswahl zuständig sind, werden allgemein als „Web Crawler“ bezeichnet.
Die Krabbler suchen nach relevanten Inhalten und bewerten, wie relevant die einzelne Website für die suchende Userin oder den User ist. Bei der Masse an Informationen und infolge des ständigen Wandels wäre es unmöglich, diese Tätigkeit von Menschen ausführen zu lassen – sie prüfen allenfalls noch, ob die Web Crawler ihre Arbeit korrekt, also entsprechend der programmierten Vorgaben, ausführen.

Geschichte: Seit wann gibt es Web Crawler?
Sicherlich fragt ihr euch, wann und aus welchem Grund der erste Web Crawler das Licht der Welt erblickt hat. Hintergrund der Entstehung dieser Bots, die auch als „Web Spider“ oder simpel als „Searchbot“ bezeichnet werden, war die zunehmende Menge an Daten im World Wide Web in den 1990er Jahren.
Im Jahr 1994 wurde der „World Wide Web Wanderer“, dessen Name man entsprechend ins Deutsche übersetzen kann, erfunden. Dieser weltweit erste Crawler hatte lediglich die Funktion, das Wachstum des Internets – also insbesondere die Zunahme der Datenmenge auf Tages-, Monats- und Jahresebene – zu messen und zu protokollieren. Schnell entdeckten die Entwickler aber weitere Einsatzmöglichkeiten, sodass aus dem Webcrawler schlussendlich die erste Suchmaschine mit sogenannter Volltextindex-Funktion entstand.
Ein Volltextindex ist die „Zusammenfassung“ aller relevanten Begriffe einer Webseite, also aller Wörter ausgenommen der sogenannten Stoppwörter. Klassische Stoppwörter sind etwa „in“, „bei“, „durch“ und sonstige Adverbien.
Heutzutage gibt es keine Suchmaschine mehr, die ohne Webcrawler arbeitet. Denn nur über die Volltextindexierung können für Userinnen und User passende Suchergebnisse gefunden und nach Relevanz sortiert werden.
Nutzen: Deshalb gibt es Webcrawler
Ein Webcrawler hat in erster Linie den Job, das Surferlebnis von Nutzern zu verbessern. Denn nur mit möglichst genauen Suchergebnissen finden sie die gewünschte Seite direkt im ersten Anlauf – und ohne Crawler wäre es kaum möglich, anhand von Faktoren wie Keywords möglichst passende Seiten direkt anzuzeigen.
Der Web Crawler hat aber auch für die Suchmaschine selbst einen entscheidenden Vorteil. Denn auf Grundlage der durchgeführten SEO Analysen lassen sich Werbeanzeigen allgemein und/oder präzise auf den jeweiligen Webseiten schalten. Für Werbekunden, an denen wiederum der Suchmaschinenbetreiber verdient, bietet sich so die Möglichkeit, noch mehr Zielgruppen anzusprechen und verhältnismäßig geringen Aufwand zu investieren.
Grundsätzliche Funktion der klassischen Webcrawler
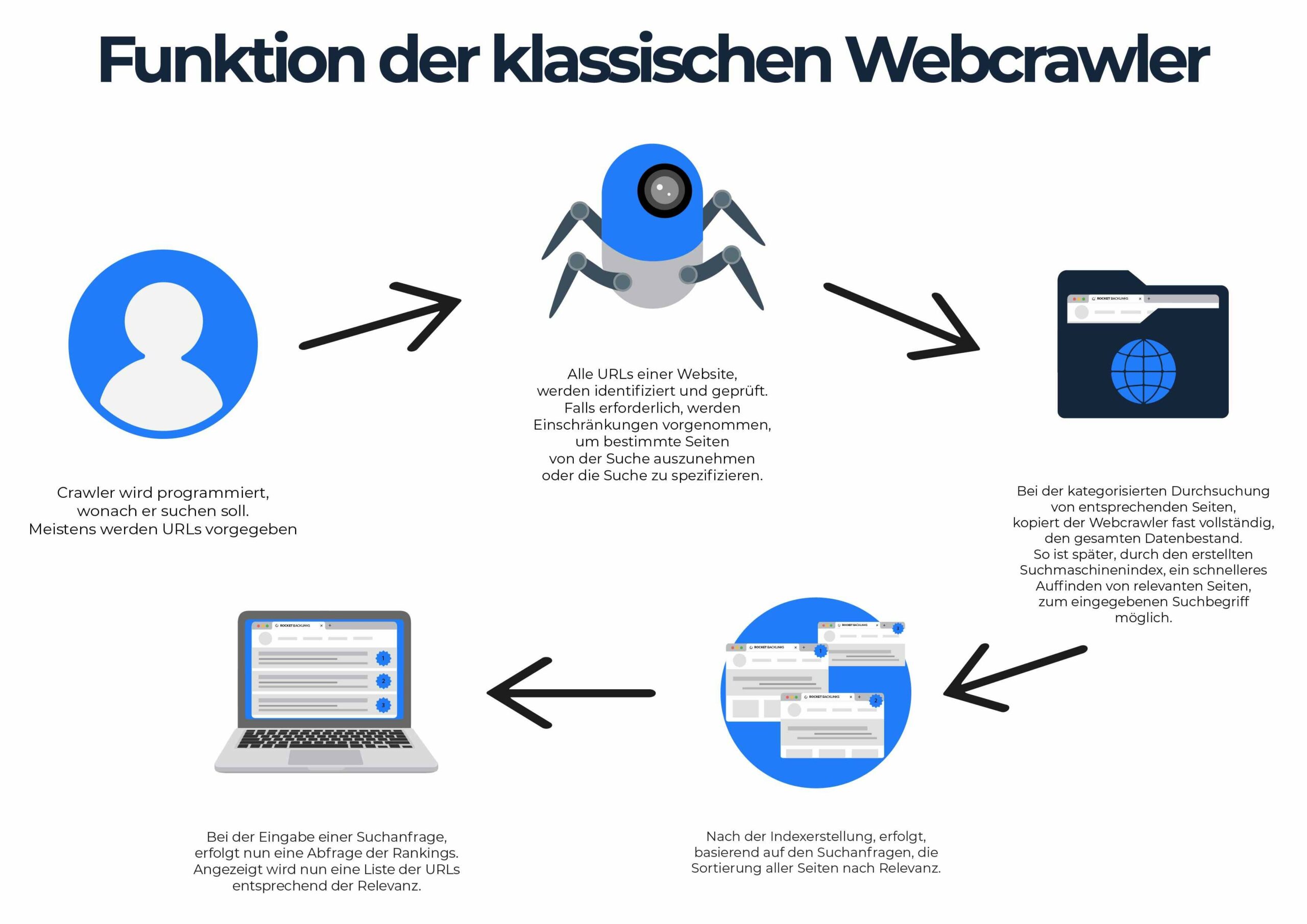
Ein Web Crawler ist nichts anderes als ein Bot, also eine Software, die automatisch sich wiederholende Tätigkeiten ausführt. Damit der Krabbler seinen Job erfüllen kann, muss er vor dem Einsatz also entsprechend programmiert und getestet werden. Die Vorgehensweise ist dabei bei allen Webcrawlern ähnlich:
- Zunächst sagt der Programmierer seinem Crawler, nach was er suchen soll. Dabei werden üblicherweise die URLs vorgegeben, wobei der Webcrawler dann alle Unterseiten der entsprechenden Links selbstständig abarbeitet.
- Im zweiten Schritt werden, falls erforderlich, Einschränkungen vorgenommen. So kann der Programmierer etwa bestimmte Seiten von der Suche ausnehmen oder vorgeben, dass nur nach definierten Unterseiten und nicht nach allen gecrawlt werden soll.
- Nach der Konfiguration beginnt der Webcrawler mit seiner eigentlichen Arbeit. Er durchsucht die entsprechenden Seiten nach den eingestellten Kriterien und erstellt dabei nahezu vollständige Kopien des gesamten Datenbestands. So ist später – also, wenn Userinnen und User ihre Suche durchführen – ein wesentlich schnellerer Zugriff auf den Index möglich, als wenn der Crawler erst dann loslegen würde.
Grundsätzlich gilt, dass Webcrawler immer nach festgelegten Kriterien und innerhalb eines limitierten Bereichs arbeiten. So können etwa nicht „alle“ Seiten des Internets gleichzeitig durchsucht werden, wodurch es dazu kommen kann, dass gerade bereitgestellte Inhalte nicht unmittelbar vom Webcrawler erfasst und in den Google-Suchergebnissen angezeigt werden.
Typischerweise geben Programmierer bei der Einstellung und Vorbereitung des Crawls dem Bot „Antworten“ auf diese Fragen:
- Wie wird die Arbeit von mehreren Crawlern, die parallel zueinander arbeiten, koordiniert, sodass sie sich nicht in die Quere kommen?
- In welchen Abständen soll der Webcrawler auf die entsprechende Seite erneut zugreifen bzw. prüfen, ob neue Inhalte verfügbar sind?
- Welche Webseiten sollen grundsätzlich nicht gecrawlt werden?
- Gibt es Kategorien, die vom Crawler in jedem Fall ignoriert werden sollen – etwa, weil sie aus SEO-Gesichtspunkten keine Relevanz haben?
- Wie lässt es sich verhindern, dass der Web Crawler durch seine zahllosen Zugriffe eine zu hohe Serverlast verursacht?
Arten von Web Crawlern: Hier liegt der Fokus
Wenngleich immer mehr Unternehmen – auch solche, die keine Suchmaschinen betreiben – Web Crawler einsetzen, wird die absolute Mehrheit der Roboter nach wie vor von letzteren betrieben. Insgesamt entfällt rund ein Drittel des weltweiten Datenverkehrs auf die Aktivität von Webcrawlern, die permanent das Internet nach neuen und relevanten Inhalten durchforsten, diese indexieren und Usern zur Verfügung stellen.
Daher ist diese Tätigkeit auch der Fokus der gängigen Web Crawler. Allerdings ist sie bei weitem nicht die einzige Aufgabe, für die die Spider genutzt werden können. Weitere Einsatzmöglichkeiten von Webcrawlern sind beispielsweise:
- Themenspezialisierte („Focused“) Crawler: Sie sind auf ein bestimmtes Thema ausgerichtet und durchforsten das World Wide Web gezielt nach Webseiten und Inhalten zu dieser Thematik. Dabei beziehen die meisten Focused-Webcrawler auch interne und externe Links auf den entsprechenden Websites mit ein.
- Plagiats-Crawler: Diese Webcrawler dienen speziell der Suche nach Plagiaten. Sie ermöglichen die Aufklärung von Urheberrechtsverstößen und werden daher in der Regel besonders fokussiert eingesetzt.
- Data-Mining-Crawler: Der Data-Mining-Crawler durchsucht das Internet (und teilweise auch das Darknet) nach Informationen einer bestimmten Kategorie, etwa gezielt Adressen. Ebenso lässt sich mit diesen Webcrawlern nach einzelnen Personen, Firmen oder Beziehungen suchen. Dabei ist sowohl die gezielte Suche als auch das allgemeine „Sammeln“ möglich.
- Reine Statistik-Crawler: Sie sammeln keine Daten, sondern messen beispielsweise lediglich, wie oft eine bestimmte Kategorie von Websites besucht wird oder inwieweit sich das Internet in bestimmten Bereichen ausbreitet.
Die verschiedenen Arten der Webcrawler macht sie sehr vielseitig einsetzbar. Je nach Geschäftsmodell des einsetzenden Unternehmens haben sie den herausgehobenen Vorteil, dass sie ein besonders effizientes, kostengünstiges und zeitsparendes Sammeln und Auswerten von Informationen aller Art möglich machen.
Generell sollten alle Webseitenbetreiber ein großes Interesse daran haben, dass ihre Auftritte möglichst häufig von Webcrawlern gefunden und als relevant eingestuft werden. So lässt sich der Traffic über die Google-Suche maximal effizient steigern.

Einsatzgebiete: Wo kommen Webcrawler überwiegend zum Einsatz?
Klassische Web Crawler dienen der Suchmaschinenoptimierung, arbeiten also nach SEO-Gesichtspunkten. Besonders relevant sind dabei die Keywords und deren Verteilung in den entsprechenden Artikeln. So kann ein Text, der zwar viele Keywords enthält, aber qualitativ schlechter als ein anderer ist, von der Suchmaschine auch durch eine schlechtere Platzierung in den Suchergebnissen „abgestraft“ werden.
Unter dem Strich sind Webcrawler damit eine entscheidende Komponente bei der Bereitstellung hochwertiger und zu den Bedürfnissen des Users am besten passender Suchergebnisse. Ohne sie wäre die Präzision moderner Suchmaschinen nicht oder nur mit erheblicher Zeitverzögerung (zeitlicher Abstand zwischen Upload der Inhalte und Auffindbarkeit bei Bing und Google) möglich.
Aber auch in vielen anderen Bereichen spielen die Crawler eine wichtige Rolle. Allgemein gehören hierzu alle Bereiche, in denen Daten zu kommerziellen Zwecken oder aus Sicherheitsgründen gesammelt werden müssen. Auch Regierungen, insbesondere Geheimdienste, setzen auf Web Crawler, um Informationen über potenzielle Risiken zu sammeln, auszuwerten und gegebenenfalls entsprechend zu reagieren.
Bekanntester Web Crawler: Der Googlebot
Beim Googlebot handelt es sich um den Webcrawler aus dem Hause Google. Er besteht aus zwei separaten Crawlern, einer davon simuliert den Zugriff vom Desktop-Rechner, der andere den Zugriff von Mobilgeräten. Wurde eine Webseite auf „Mobile First“ eingerichtet, greift der mobile Crawler etwas häufiger zu als der Desktop-Crawler – entsprechendes gilt andersherum.
Hintergrund: Seiten, die vorrangig für mobile Zugriffe optimiert werden, haben aus Googles Sicht auch eine höhere Relevanz für Userinnen und User, die mit ihrem Smartphone oder Tablet im Netz unterwegs sind. Daher möchte Google das Nutzererlebnis möglichst gut auf diese Zielgruppe zuschneiden.
Der Googlebot greift im Schnitt im Abstand weniger Sekunden auf einzelne Websites zu, um die Serverkapazität möglichst wenig auszureizen. Sollte das Crawling dennoch zu Leistungseinbußen führen, können Seitenbetreiber bei Google eine Änderung der sogenannten Crawling-Frequenz beantragen.
Der Googlebot beschränkt sein Crawling dabei auf die ersten 15 MB einer Seite. Für die meisten Betreiber hat dieses Limit keine Auswirkung, da die Median-Seite nur rund 30 KB groß ist. Die Größe einer Page lässt sich beispielsweise über die Chrome-Entwicklertools herausfinden. Übrigens: Für Bilder und Videos, die im HTML-Code mit einer separaten URL enthalten sind, gilt das Limit nicht. Denn sie werden vom Crawler getrennt indexiert.
Außerdem ist es möglich, den Googlebot zu blockieren. Dass er gar nicht auf die Webseite findet, ist in der Praxis aber kaum möglich – denn sobald auch nur eine Verlinkung auf die „unsichtbare“ Seite oder von ihr auf eine andere Seite führt, taucht der entsprechende Link in den Verweisen der anderen Website auf und kann dort vom Google-Webcrawler wieder gefunden werden. Allerdings können Userinnen und User den Bot auch manuell deaktivieren, indem sie entweder das Crawling unterbinden, die Indexierung ausschalten oder den Seitenzugriff generell verbieten.
Allgemein gilt: Webcrawler führen nur dann Indexierungen durch und zeigen Websites in den Suchergebnissen an, wenn die oder der Suchende auch auf die Seite zugreifen können. Ist der Zugriff auf eine Website nicht möglich, wird sie automatisch auch nicht gecrawlt.
Einschränkungen: So kann der Webcrawler behindert werden
Wie oben bereits erwähnt, sollte das Ziel grundsätzlich sein, seine Website möglichst auf das Crawling zu optimieren. Einige Probleme und Einschränkungen und wie sie sich einfach beheben lassen:
- Unlogische URL-Struktur: Je logischer die Struktur der Website, desto leichter und öfter kann sie gecrawlt werden – und umso relevanter wird sie für Bing, Google und Co.
- Zu wenige Backlinks: Je weniger interne und externe Verlinkungen es gibt, desto kürzer dauert das Crawling und desto irrelevanter wird die Seite für die Suchmaschine
- Anmeldung erforderlich: Da ein Crawler immer einen suchenden User simuliert, kann dieser nicht auf die Seite zugreifen, wenn für den Zugriff auf die entsprechenden Inhalte eine Anmeldung notwendig ist. Es sollte daher immer einen (großen) Bereich auf der Website geben, der keine Anmeldung erfordert
- Netzwerkbeschränkung: Auch Webseiten, die sich in einem geschlossenen IP-Netzwerk befinden, kann der Webcrawler nicht oder nur eingeschränkt finden
- Viele Weiterleitungen: Grundsätzlich sind Links beim Crawling eine feine Sache. Sie müssen aber einwandfrei funktionieren und korrekt implementiert sein, damit der Crawler ihnen folgen kann. Sonst kommt es zu Verzögerungen und möglicherweise zur Überlastung des Servers

Crawl erneut durchführen: Besonders bei neuem Content sinnvoll
Besonders wenn User neuen Content auf ihre Website hochladen, ist ein erneutes Crawling sinnvoll. Da es bis zur erneuten automatischen Indexierung möglicherweise mehrere Tage oder sogar Wochen dauert, könnten User den Crawl selbst anstoßen. Beim Googlebot gibt es hierfür mehrere Methoden, um das Verfahren zumindest zu beschleunigen.
Grundsätzlich gilt: Das Crawling kann durchaus mehrere Tage in Anspruch nehmen. Userinnen und User sollten also nicht zu ungeduldig sein, da auch mehrere Support-Anfragen den Vorgang nicht beschleunigen.
Mit dem Google-eigenen URL-Prüftool können Nutzer einzelne URLs crawlen lassen. Dabei wird die URL zunächst eingegeben und von Google geprüft. Mit einem anschließenden Klick auf „Indexierung beantragen“ führt das Tool automatisch einen Live-Test durch und prüft oberflächlich, ob es bereits erkennbare, offensichtliche Probleme mit der Indexierung geben könnte. Falls nicht, wird der Antrag in die Warteschlange eingereiht.
Sollen mehrere URLs geprüft werden, ist die Einreichung einer Sitemap zu empfehlen. Sie kann in den Formaten XML, RSS, mRSS, Atom 1.0 und Text erstellt und an Google übermittelt werden. Content-Management-Systeme wie WordPress bieten eine integrierte Funktion zur automatischen Sitemap-Erstellung, die das Verfahren deutlich beschleunigt.
Fazit: Web Crawler – eine Faszination für sich
Webcrawler erfüllen zahlreiche Aufgaben und sind maßgeblich dafür verantwortlich, dass wir das Internet so nutzen können, wie wir es heute gewohnt sind. Ohne die kleinen Bots, die mehr oder weniger unsichtbar das gesamte Netz nach relevanten Inhalten für Suchmaschinen, Werbe- und sonstige Unternehmen durchsuchen, würden interessante Suchergebnisse entweder gar nicht oder erst mit deutlicher Zeitverzögerung auftauchen.
Für Blog- und Seitenbetreiber aller Art gilt: Website crawling-freundlich gestalten! Einfache URL-Struktur, viele interne Links, SEO-Optimierung, kein oder nur ein kleiner geschützter Anmeldebereich – all das sind Faktoren, die die Indexierung und damit die Auffindbarkeit bei Google wesentlich verbessern. Wir empfehlen: Einfach mal ausprobieren!
Einzelnachweise

Web Crawler: Geschichte, Funktion und praktischer Nutzen der „Krabbler“
Author:Jakob Friesen
Datum:01.03.2022
Inhaltsverzeichnis
- Allgemeines zu Web Crawlern
- Geschichte: Seit wann gibt es Web Crawler?
- Nutzen: Deshalb gibt es Webcrawler
- Grundsätzliche Funktion der klassischen Webcrawler
- Arten von Web Crawlern: Hier liegt der Fokus
- Einsatzgebiete: Wo kommen Webcrawler überwiegend zum Einsatz?
- Bekanntester Web Crawler: Der Googlebot
- Einschränkungen: So kann der Webcrawler behindert werden
- Crawl erneut durchführen: Besonders bei neuem Content sinnvoll
- Fazit: Web Crawler – eine Faszination für sich

Informationen oder haben
sonstige Fragen?
Klicken Sie auf eine der Kontaktmöglichkeiten - wir freuen uns über Ihren Kontakt!
